
Mic check/intro
48 years and five days ago, on June 16, a boy named Lesane Parish Crooks was born. This is my way of remembering your birthday, Pac. “Make sure it’s poppin’ when we get up there, man, don’t front”.
Rap music has been one of the most influential music genres for the biggest part of the last quarter century. It all started by the name of “Rhythm and Poetry”, meaning, words mean the world here. This NLP data analysis will try to shed more light on the way the most influential rappers, well, rap.
The purpose of this NLP project is to analyze 5 songs per rapper. Therefore, we analyze 7 rappers, meaning our data will contain lyrics from 35 songs. The goal of our analysis is to make conclusions on the positivity and the subjectivity of the rappers, as well as the size of their vocabulary.
This project, as hopefully every other data science project, will go through the notorious process of “Data Cleaning”. It’s boring and all that, yet it’s absolutely vital for the sanity of our results. If you put sour food in the juicer, you can’t really expect not to get sour juice, right? Feed a model with bad data, it feeds you with bad results. In the world of data science, it’s almost impossible to completely clean your data, yet we should always try to minimize the garbage. So, we can maximize the correctness of our output.
Clean data is not enough. We need properly structured data. Why? Well, algorithms have a thing for properly structured data. Organizing data in the right way makes it easier for algorithms to extract better information.
It’s worth noting that the choice of rappers and songs is totally subjective. Hence, you could do this analysis for any musician, author, poet or any other text content producer. Good luck with cleaning data for mumble rap lyrics though.
First of all, let’s see the final list of steps we will go through before we actually do some really cool stuff with our data:
1. Obtain data
2. Clean data
3. Structure data
i. Corpus – a collection of song lyrics from every rapper
ii.Word Matrix – matrix format of every word used in the Corpus
As we will notice, the “Clean data” and “Structure data” steps are dependent and could be executed in parallel.
Obtain, Clean, Structure
1. Obtain data
Here is the list of rappers and songs we will obtain data for:
1. Tupac Amaru Shakur
– “Life Goes On”
– “Unconditional Love”
– “Changes”
– “Until The End Of Time”
– “Dear Mama”
2. The Notorious B.I.G.
– “Ten Crack Commandments”
– “Hypnotize”
– “Juicy”
– “One More Chance”
– “Big Poppa”
3. Snoop Doggy Dogg
– “What’s My Name?”
– “Gin And Juice”
– “That’s That Shit”
– “The Doggfather”
– “Eastside Party”
4. Nas
– “N.Y. State Of Mind”
– “Nas Is Like”
– “Surviving The Times”
– “The Message”
– “Memory Lane”
5. The Game
– “Where I’m From”
– “One Night”
– “Don’t Need That Love”
– “Laugh”
– “Too Much”
6. 50 Cent
– “Hustler’s Ambition”
– “Window Shopper”
– “If I Can’t”
– “Many Men”
– “When It Rains It Pours”
7. Eminem
– “Rap God”
– “Phenomenal”
– “Wicked ways”
– “Kinds never die”
– “The ringer”
Hence, we will find the lyrics on ********* and store the URLs in variables:
# We will use Requests and BeatufiulSoup for scraping import requests from bs4 import BeautifulSoup # We will use Pickle and OS to create folders and store files import pickle import os # We will use Pandas to structure and maintain our data import pandas # We will use Re and String modules when we start cleaning our data import re import string # We will use this module in the 'Cleaning Data' and 'Structure Data' steps from sklearn.feature_extraction.text import CountVectorizer # Storing URLs to the Tupac songs lyrics tupac_urls = [] # Storing URLs to the Biggie songs lyrics biggie_urls = [] # Storing URLs to the Snoop songs lyrics snoop_urls = [] # Storing URLs to the Nas songs lyrics nas_urls = [] # Storing URLs to the The Game songs lyrics game_urls = [] # Storing URLs to the 50 Cent songs lyrics fifty_urls = [] #Storing URLs to the Eminem songs lyrics eminem_urls = []
Next, we need a function that will take a URL and return the scraped text.
# Function that takes a URL as parameter, scrapes the ******* page at that URL, extracts and returns the lyrics
def fetch_lyrics(url):
print(url)
page = requests.get(url)
html = BeautifulSoup(page.text, "html.parser")
lyrics = html.find("div", class_="lyrics").get_text()
return lyrics
Now that we have a function, we will use it to fetch lyrics. This could take a couple of minutes. Finally, you will see the URL of the scraped page printed out.
# We will store the lyrics in this dictionary
lyrics = {}
lyrics['tupac'] = [fetch_lyrics(url) for url in tupac_urls]
lyrics['biggie'] = [fetch_lyrics(url) for url in biggie_urls]
lyrics['snoop'] = [fetch_lyrics(url) for url in snoop_urls]
lyrics['nas'] = [fetch_lyrics(url) for url in nas_urls]
lyrics['game'] = [fetch_lyrics(url) for url in game_urls]
lyrics['fifty'] = [fetch_lyrics(url) for url in fifty_urls]
lyrics['eminem'] = [fetch_lyrics(url) for url in eminem_urls]
We could print out the lyrics collection for one rapper just to see that our scraping was successful.
#print(lyrics['tupac'])
Now that we have scraped our data, we need to organize it. We will save the lyrics collection for every rapper in a separate file using Pickle, which we imported at the start. Pickle is used in Python for object serialization. Therefore, the files will be saved in a directory that we will create if it doesn’t already exist.
# Create the directory where we will keep the lyrics files
if not os.path.exists('lyrics'):
os.makedirs('lyrics')
rappers = ['tupac', 'biggie', 'snoop', 'nas', 'game', 'fifty', ''eminem]
# Create named files
for i, rapper in enumerate(rappers):
with open("lyrics/" + rapper + ".txt", "wb") as file:
pickle.dump(lyrics[rapper], file)
We will read the data from the files. Then we’ll apply a few cleaning techniques to it.
data = {}
for i, rapper in enumerate(rappers):
with open("lyrics/" + rapper + ".txt", "rb") as file:
data[rapper] = pickle.load(file)
At this point, you could check if the data was loaded correctly. We are done with obtaining data, now we proceed to the second step, cleaning data.
#data.keys() #data['tupac']
Notice that we actually have a list of song lyrics instead of one single text.
2. Clean data
The techniques used to clean textual data are called “text pre-processing techniques”. We will use a few of those, but won’t go to any advanced data cleaning. We will go through the following techniques:
1. Remove garbage characters (like “/n”, “[]” and so on)
2. Remove punctuation
3. Remove numerical values
4. Make all text lowercase
5. Remove stop words
Consequently, we will structure the data in a better way. As noticed before, our data per rapper is a list of lyrics. So, we have to transform it into one single text. We will write a function that will accept a list of lyrics and will return one single text. That can only mean one thing…
3. Structure data
First of all, we will merge our data into a single text, and then we will put it in the following formats:
- Corpus – a collection of song lyrics from every rapper
- Word Matrix – matrix format of every word used in the Corpus
We will move back and forth between cleaning and structuring data, as we can’t efficiently clean badly structured data.
def merge_lyrics(list_of_lyrics):
merged_text = ' '.join(list_of_lyrics)
return merged_text
merged_data = {key: [merge_lyrics(value)] for (key, value) in data.items()}
Let’s try it out. We will print the data before and after executing this function.
#data['tupac'] #merged_data['tupac']
That’s better. Our data at the moment is in the dictionary format. We will put it in pandas dataframe, or we will re-structure it.
We kinda already have our data in the Corpus format, now we will create Pandas dataframe from it. Why? Because it will be easier to clean our data if it is structured in a dataframe.
pandas.set_option('max_colwidth',150)
lyrics_dataframe = pandas.DataFrame.from_dict(merged_data).transpose()
lyrics_dataframe.columns = ['lyrics']
lyrics_dataframe = lyrics_dataframe.sort_index()
We will check to see if our dataframe is what we expect it to be.
#lyrics_dataframe
Now we could take a look at Tupac’s (or any other rapper’s) data.
#lyrics_dataframe.lyrics.loc['tupac']
Now that we have our data restructured we move on to the second data cleaning technique that we will apply: remove garbage characters.
def remove_garbage_characters(lyrics):
# remove data in brackets
lyrics = re.sub('\[.*?\]', '', lyrics)
# remove multiple "\n" characters with ''
lyrics = re.sub('\n{2,}', '', lyrics)
# remove single "\n" character with ' '
lyrics = re.sub('\n', ' ', lyrics)
return lyrics
garbage_characters_removal_technique = lambda x: remove_garbage_characters(x)
clean_data = pandas.DataFrame(lyrics_dataframe.lyrics.apply(garbage_characters_removal_technique))
We could check to see if there are any changes in the data.
#clean_data.lyrics.loc['tupac']
Then, we move on to the third data cleaning step: remove all punctuation.
def remove_punctuation(lyrics):
lyrics = re.sub('[%s]' % re.escape(string.punctuation), '', lyrics)
lyrics = re.sub('[‘’“”…]', '', lyrics)
return lyrics
remove_punctuation_technique = lambda x: remove_punctuation(x)
clean_data = pandas.DataFrame(clean_data.lyrics.apply(remove_punctuation_technique))
See where we are:
#clean_data.lyrics.loc['tupac']
That’s beautiful. If you run the last line of code, you will notice that we still have numbers in the text. Certainly, we don’t need numbers, so let’s remove them.
def remove_numerical_values(lyrics):
lyrics = re.sub('\w*\d\w*', '', lyrics)
return lyrics
remove_numerical_values_technique = lambda x: remove_numerical_values(x)
clean_data = pandas.DataFrame(clean_data.lyrics.apply(remove_numerical_values_technique))
#clean_data.lyrics.loc['tupac']
Do you see any numbers? I don’t. Seems like we are doing good. Let’s make all text lowercase now.
def transform_to_lowercase(lyrics):
lyrics = lyrics.lower()
return lyrics
transform_to_lowercase_technique = lambda x: transform_to_lowercase(x)
clean_data = pandas.DataFrame(clean_data.lyrics.apply(transform_to_lowercase_technique))
Let’s check it out.
#clean_data.lyrics.loc['tupac']
We will now add the full artist name of the rappers in our dataframe.
rappers_full_names = ['The Notorious B.I.G.', 'Eminem', '50 Cent', 'The Game', 'Nas', 'Snoop Doggy Dogg', 'Tupac Amaru']
clean_data['name'] = rappers_full_names
clean_data.to_pickle("corpus.pkl")
clean_data
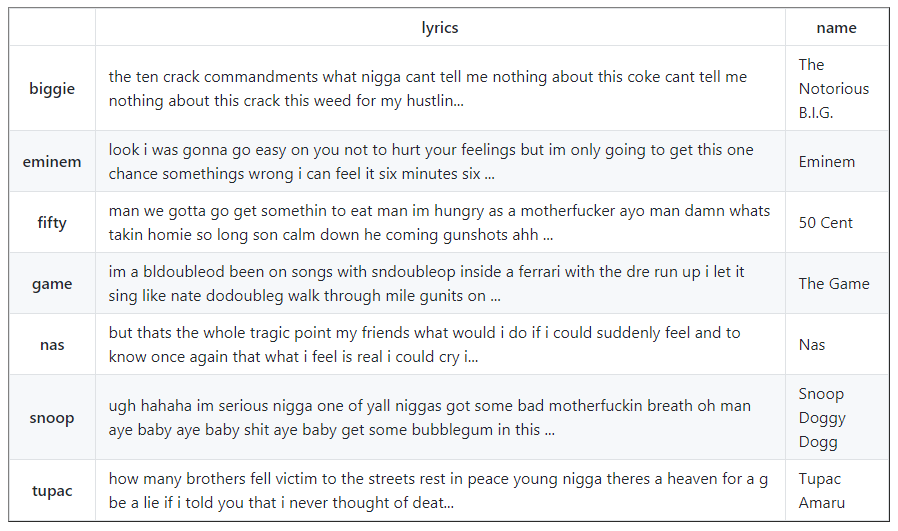
Now let’s move on to the last step of our data cleaning process: remove stop words. But, before we do that, we have to organize our data in a word matrix. We will use CountVectorizer to tokenize the lyrics and we can remove the stop words with the same module. Every row will contain data for a rapper and every column will be a different word.
cv = CountVectorizer(stop_words='english') tokenized_data = cv.fit_transform(clean_data.lyrics) word_matrix = pandas.DataFrame(tokenized_data.toarray(), columns=cv.get_feature_names()) word_matrix.index = clean_data.index
Let’s see our word matrix:
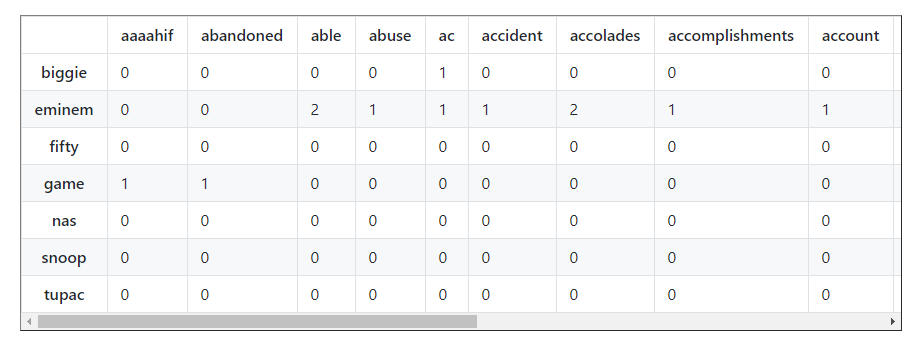
7 rows × 3890 columns
Finally, we will save all data to files:
cv = CountVectorizer(stop_words='english') tokenized_data = cv.fit_transform(clean_data.lyrics) word_matrix = pandas.DataFrame(tokenized_data.toarray(), columns=cv.get_feature_names()) word_matrix.index = clean_data.index
Exploratory Data Analysis
Mic Check / Intro
By this point, we have our data as clean and as well structured as possible. Before we go on and apply some cool algorithms to our data, we should first explore and make some basic conclusions about it.
The exploratory data analysis techniques (EDA) are some common patterns which are used to extract some basic information about the distribution of the data, the most common values and so on. The patterns we can conclude from EDA techniques are called “visible”, those that require fancy algorithms are called “hidden”. Smart, right?
We will make conclusions on the following 3 questions:
1. What are the most common words used by each rapper?
2. What is the size of the vocabulary (unique words) used by each rapper?
3. What rapper swears the most?
1. What are the most common words used by each rapper?
This question requires that we examine the words separately, that’s why we are so lucky to have our words matrix. Let’s read it in from the file.
import pandas
from sklearn.feature_extraction import text
from sklearn.feature_extraction.text import CountVectorizer
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import pickle
import numpy as np
data = pandas.read_pickle('word_matrix.pkl')
data = data.transpose()
data.head()
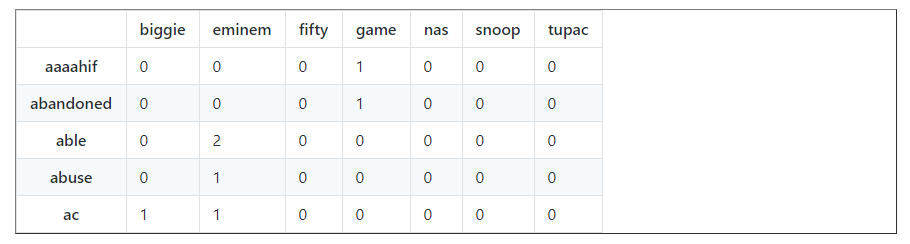
Now let’s find the top 50 most commonly used words for each rapper.
top_50 = {}
for c in data.columns:
top = data[c].sort_values(ascending=False).head(50)
top_50[c]= list(zip(top.index, top.values))
Let’s take a look at our results.
#top_50
Now, we see that some of these words are just stop words and have no real meaning. Furthermore, we will try to remove them:
# Get the stop words registered in the library
stop_words = text.ENGLISH_STOP_WORDS
clean_data = pandas.read_pickle('clean_data.pkl')
# Update the word matrix
cv = CountVectorizer(stop_words=stop_words)
data_cv = cv.fit_transform(clean_data.lyrics)
data_non_stop_words = pandas.DataFrame(data_cv.toarray(), columns=cv.get_feature_names())
data_non_stop_words.index = clean_data.index
# We will save the updated word matrix
pickle.dump(cv, open("cv_stop.pkl", "wb"))
data_non_stop_words.to_pickle("data_non_stop_words.pkl")
Now let’s see if our data is clean of stop words.
data = pandas.read_pickle('word_matrix.pkl')
data = data.transpose()
data.head()
top_50 = {}
for c in data.columns:
top = data[c].sort_values(ascending=False).head(50)
top_50[c]= list(zip(top.index, top.values))
#top_50
This one is exciting. Let’s create word clouds of the 50 most commonly used words for each rapper.
word_cloud = WordCloud(stopwords=stop_words, background_color="white", colormap="Dark2",
max_font_size=150, random_state=42)
plt.rcParams['figure.figsize'] = [16, 6]
rappers_data = ';'.join(data.columns)
rappers = []
for item in rappers_data.split(';'): # comma, or other
rappers.append(item)
rappers_full_names = ['The Notorious B.I.G.', 'Eminem', '50 Cent', 'The Game', 'Nas', 'Snoop Dogg', 'Tupac Amaru']
for i, rapper in enumerate(data.columns):
word_cloud.generate(clean_data.lyrics[rapper])
plt.subplot(3, 4, i+1)
plt.imshow(word_cloud, interpolation="bilinear")
plt.axis("off")
plt.title(rappers_full_names[i])
plt.show()

So, what is the answer to the question “What are the most common words used by each rapper”?
For B.I.G., 50 Cent, The Game and Nas is the ‘N’ word, Snoop likes to ‘put some respect on his name’, and Tupac talks about time and his mother.
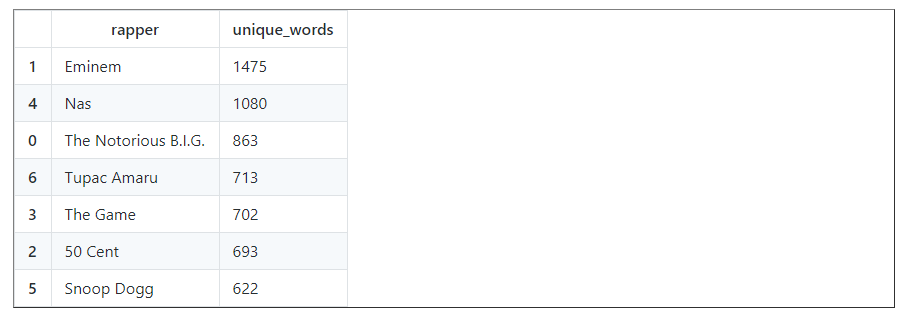
2. What is the size of the vocabulary (unique words) used by each rapper?
We will try to find out how many different words each rapper uses.
unique_words = []
for rapper in data.columns:
uniques = (data[rapper]).to_numpy().nonzero()[0].size
unique_words.append(uniques)
unique_words
#We will put the unique word count in a dataframe
data_words = pandas.DataFrame(list(zip(rappers_full_names, unique_words)), columns=['rapper', 'unique_words'])
data_unique_sort = data_words.sort_values(by='unique_words', ascending=False)
data_unique_sort
Now, let’s add the total number of words for each rapper to this table.
# Find the total number of words that a comedian uses
total_words_list = []
for rapper in data.columns:
totals = sum(data[rapper])
total_words_list.append(totals)
# Let's add some columns to our dataframe
data_words['Total words #'] = total_words_list
# Sort the dataframe by words per minute to see who talks the slowest and fastest
data_words
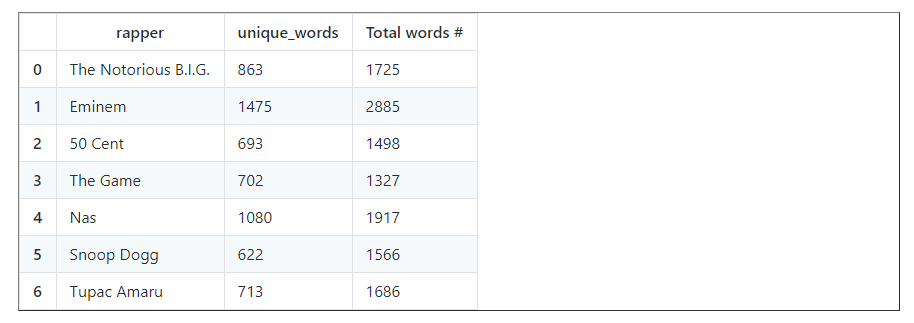
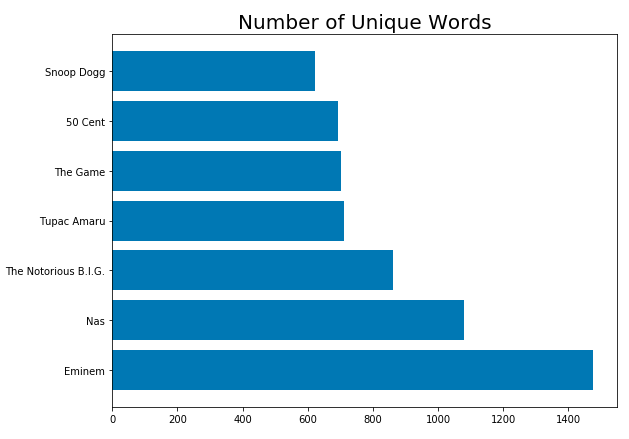
Hence, we can see that Eminem used the most unique and has the longest verses. Let’s plot the unique words analysis:
y_pos = np.arange(len(data_words))
plt.subplot(1, 2, 1)
plt.barh(y_pos, data_unique_sort.unique_words, align='center')
plt.yticks(y_pos, data_unique_sort.rapper)
plt.title('Number of Unique Words', fontsize=20)
plt.tight_layout()
plt.show()
Finally, let’s finish the Exploratory Data Analysis with the third technique.
3. What rapper swears the most?
swear_words = data.transpose()[['bitch', 'nigga', 'fucking', 'fuck', 'shit']] data_swear_words = pandas.concat([swear_words.nigga, swear_words.bitch, swear_words.fucking + swear_words.fuck, swear_words.shit], axis=1) data_swear_words.columns = ['nigga', 'bitch', 'fuck', 'shit'] data_swear_words
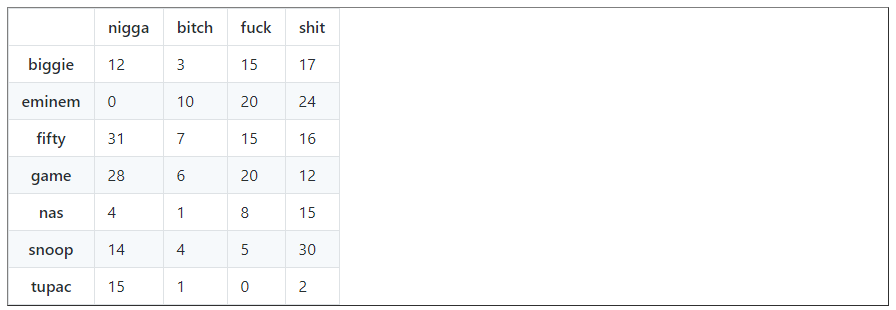
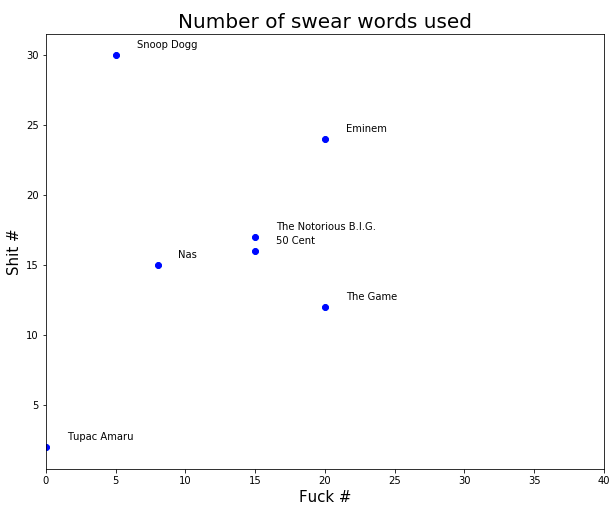
Tupac is doing quite well in comparison with the others. As a result, we will plot the two most used words: the ‘N’ word and ‘sh*t’.
plt.rcParams['figure.figsize'] = [10, 8]
for i, rapper in enumerate(data_swear_words.index):
print(rapper)
x = data_swear_words.nigga.loc[rapper]
y = data_swear_words.shit.loc[rapper]
plt.scatter(x, y, color='blue')
plt.text(x+1.5, y+0.5, rappers_full_names[i], fontsize=10)
plt.xlim(0, 40)
plt.title('Number of swear words used', fontsize=20)
plt.xlabel('Nigga #', fontsize=15)
plt.ylabel('Shit #', fontsize=15)
plt.show()
biggie
eminem
fifty
game
nas
snoop
tupac
Hence, we can be satisfied with what we got as results. It’s not perfect and we could definitely clean our data a lot better. But it’s sufficient for now. As a reminder, we went through 3 different EDA (Exploratory Data Analysis) techniques and each gave us some different conclusion. Therefore, our basic NLP data analysis was a success, now we go on to do the real thing.
Sentiment Analysis
Mic Check / Intro
We are about to perform sentiment analysis using TextBlob to process our data. What is TextBlob?
TextBlob is a Python (2 and 3) library for processing textual data. It provides a simple API for diving into common natural language processing (NLP) tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, classification, translation, and more. [docs]
So, our goal is to label every word in a corpus in terms of polarity and subjectivity. A corpus’ sentiment is the average of these.
- Polarity: How positive or negative a word is. -1 is very negative. +1 is very positive.
- Subjectivity: How subjective, or opinionated a word is. 0 is fact. +1 is very much an opinion.
import pandas
from textblob import TextBlob
import matplotlib.pyplot as plt
data = pandas.read_pickle('corpus.pkl')
Let’s first take a look at the state of our data.
data
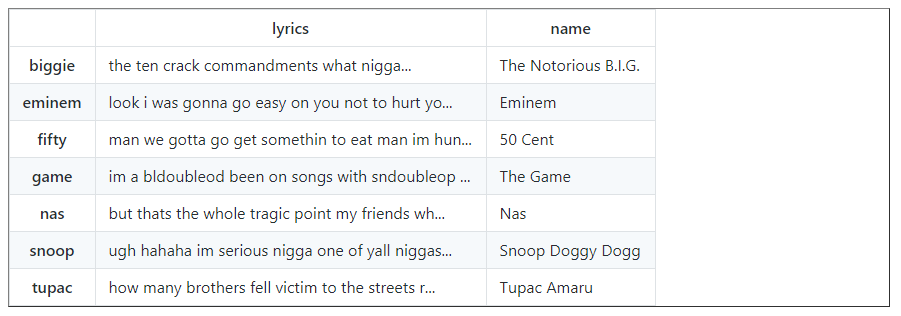
Next stop: we will create lambda functions to calculate the polarity and subjectivity of each rapper.
pol = lambda x: TextBlob(x).sentiment.polarity sub = lambda x: TextBlob(x).sentiment.subjectivity data['polarity'] = data['lyrics'].apply(pol) data['subjectivity'] = data['lyrics'].apply(sub) data
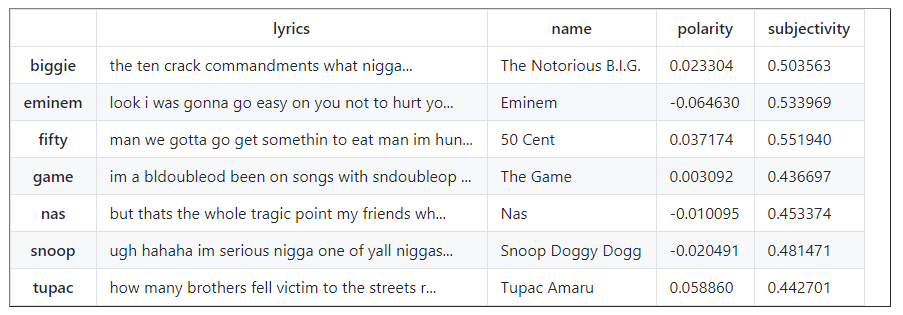
Well, that’s something. We now know that Tupac is the most positive. In addition, he is the least subjective in his lyrics, while 50 Cent is most subjective.
But, how does TextBlob know what words mean? Well, linguists have given different labels to all the words in the English vocabulary and TextBlob is a library that wraps that knowledge. Let’s see an example:
TextBlob('good').sentiment
Sentiment(polarity=0.7, subjectivity=0.6000000000000001)
TextBlob('very good').sentiment
Sentiment(polarity=0.9099999999999999, subjectivity=0.7800000000000001)
TextBlob('excellent').sentiment
Sentiment(polarity=1.0, subjectivity=1.0)
The output says that the word ‘nice’ transmits 60% of the positivity a word can transmit, while it’s 100% of subjective nature.
plt.rcParams['figure.figsize'] = [10, 8]
for index, rapper in enumerate(data.index):
x = data.polarity.loc[rapper]
y = data.subjectivity.loc[rapper]
plt.scatter(x, y, color='blue')
plt.text(x+.001, y+.001, data['name'][index], fontsize=10)
plt.xlim(-.03, .07)
plt.title('Sentiment Analysis', fontsize=20)
plt.xlabel('Positivity', fontsize=15)
plt.ylabel('Objectivity', fontsize=15)
plt.show()
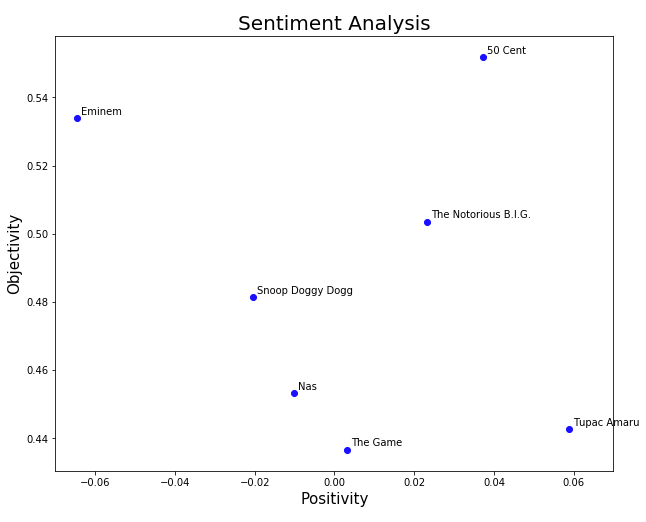
The conclusion from the sentiment analysis:
- Tupac is the most ‘positive’ in his words, while Eminem is by far the most ‘negative’ lyricist
- The Game, Nas, and Tupac are mostly subjective and talk about their feelings, while Eminem and 50 Cent state more facts
Mic Drop
I hope you liked my broad NLP analysis of the content I’ve chosen. Remember, it’s only up to you to choose which data you want to analyze and what you want to find out.
The ongoing process itself will lead you to the next steps. Moreover, your intuition will lead you to the end.
Being here at the very end of this post, I’ve prepared something for you -> here’s the code playground where you can try it for yourself and have fun.
Got any questions? Feel free to reach me out at boban.sugareski[at]gsix.me or comment down below 👇
Till next time ✌
{kind=link}
Comment